Hello!
I’ve been using Tropy for about a year and so far I had found it extremely useful. Lately, however, it’s not been working well. Perhaps it is related to the fact that I’ve been importing more multiple-image PDFs (I usually trim them so I only import 15 images at a time) instead of JPGs.
Tropy often stalls when I try to go from item to item, or from one photo to the other within the same item. Importing 15-image PDFs often takes longer than half an hour. If I leave Tropy importing a file while doing something else, my entire computer slows down a lot, which doesn’t happen otherwise. My notes sometimes my notes disappear and then reappear after I’ve re-typed them.
For instance, I am now trying to access one item while importing an 8-page PDF and the result is the screenshot attached.
I use Windows 10. Is there anything I can do to fix this?
Thank you!
Wow, we have not seen anything like this before. Thanks for reporting!
Importing PDFs can potentially take a long time. Each page has to be rasterized (i.e., turned into a pixel based image) at a given resolution. Depending on the PDF in questions (or more precisely, on the images embedded in the PDF) the resolution can play a big role on whether the generated images are of good quality but also not bigger than they need to be. In general, if the problems are connected with PDFs I could immediately think of two potential causes: it’s possible that the generated images are much larger than they need to be – handling large images can have a big impact on the memory and GPU footprint, thus affecting your system adversely – or that there are some issues with the WebP format (Tropy currently saves those generated images as WebP and we’ve seen that this can cause issues in some settings).
We’ll be addressing the WebP issue in an upcoming release, so in the meantime, one thing you could is to check how big the individual pages of the PDF are. If they are very large, you can try to change the pixel resolution (in the photo metadata panel) – after changing the resolution, the page should be generated (and will become larger or smaller, based on the new resolution).
This is, of course, assuming that PDFs are to blame; you could also send us a tropy.log file from a session where these slowdowns occurs – maybe we’ll be able to learn something from them.
Thank you very much for your quick answer!
I’m not sure how to find out the size of the individual pages. If it is as simple as dividing the size of the file for the number of pages, it looks like they weigh around 500KB each–so, lighter than some JPGs I used to work with.
I’ll send you the tropy.log file.
Thanks again!
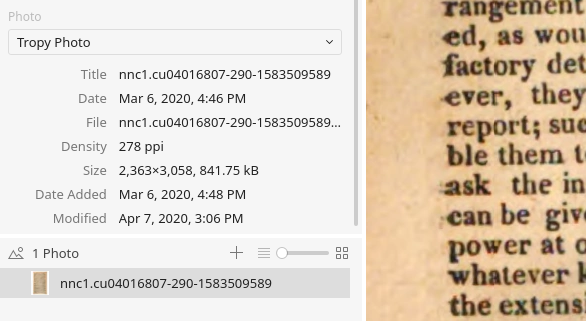
The file size is misleading for PDFs, because it’s the size of the PDF itself, not of the individual rasterized page. In any case, if you look at the screenshot above, this shows the photo’s metadata in the metadata panel – I would be most interested in the ‘Density’ and the pixel resolution, which is the first part of the ‘Size’ value. For instance, in the screenshot above it’s 2,363 by 3,058 pixels at 278 ppi.
Got it, thank you for the explanation! This may be the problem, then. I selected a random PDF and the density is 8,350 by 12,525 pixels at 300 ppi.
OK this may be a reason why Tropy struggles with this PDF. If you change the density, for instance to 72, the image should re-generate and be much smaller: if the quality is not good, you can increase the ppi again (e.g. to 144) to see if that’s better. If there are many pages in the PDF, you can also change the default ppi in the preferences and import the PDF again (if that’s faster than changing all the pages individually).
Unfortunately, the ideal ppi may differ from page to page (it depends on the quality of the embedded images) – if you have a tool like pdfimages at your disposal, it’s relatively easy to check the ppi of the embedded images in order to know the optimal setting for this particular PDF. But just in general it’s a good idea to start at 72 and increase it until you the quality of the result is satisfying.
You should start using pdf.js and a quickview library that support PDF rendering, why all the overlay by extracting and generating bitmaps of a pdf?
with PDF.js you could support annotations in PDF…
I really don’t understand why you go that way, with all the overlay and unneccessary resourch usage and possible error/faults this extraction will give…
Sorry that I’m a little harse here, but I really do not understand this way of thinking…
As I have understud, you also work with Zotero, why dont you use some effort to combine the two, and use already known code and libraries for things?
Its no point reinvent the wheel?
This actually remind me a lot of Norwegian academics… reinventing any system they shall use… even though there are lots of greats tools out there already…
Sorry that I’m a little harse here, but I really do not understand that way of thinking…
Tropy is an application that works with raster graphics; this is not unlike an application like Photoshop: when you import a PDF into such tools, the pages will also be converted into images. Consequently, Tropy’s PDF support is mainly intended to cover PDFs which are, essentially, containers for embedded images – many of our users have those, because they are a convenient (though not ideal) means to store multiple images together in an easily viewable and transferable way.
You can also import PDFs with no embedded images into Tropy, of course, but that’s certainly not the same as using a PDF viewer. As I’ve mentioned elsewhere, we’re considering extracting text as an option, but the main reason why we’re cautious to do this is precisely because we do not want to, as you put it, reinvent the wheel: to support PDFs for real, as it were, it would be much better to replace Tropy’s image viewer wholesale with a PDF component. This is certainly an intriguing perspective: in fact, supporting not only PDFs, but also video, audio, and other text files comes to mind, all of which would warrant dedicated ‘viewer’ components with different features (text selection, annotation, voice transcriptions, etc.).
Using PDF.js for such a dedicated PDF component is certainly a good suggestion; however, as someone who has embedded PDF.js into a major application before the idea to “just use known libraries for things” grossly underestimates the amount of effort of such an endeavor.
As it stands, Tropy is an application built for organizing photos; its viewer component is dedicated to displaying images, to provide good rendering quality across different scale options and resolutions, as well as various filters which all operate at the pixel level. Tropy’s metadata model is generic enough to potentially support other subjects of interest, such texts, audio or video recordings and it’s certainly possible that future development cycles will have us embrace this direction – and I encourage you to support us if this is a direction you would like the project to take.
