This sounds like a good approach. I’m aware of a similar import workflow, and the corresponding forums thread, that might be worth looking up. I will say a few general words about the JSON import into Tropy below and of course we can help in your specific case, if you have any question later on.
The most important thing to decide at the outset, is how your data maps to Tropy items, photos (and perhaps even selections): by definition, there is a 1:1 relationship between your images and Tropy photos. In the case of a PDF or a multi-page TIFF this means that each page will end-up in Tropy as a photo. These photos can either correspond to one item, respectively, or they can be grouped together. In your case, I would start with the assumption that each of your PDF files is a Tropy item, and each page a photo in that item – but you should definitely consider if it would be useful to break out smaller items.
This is slightly off-topic to import, but basically, the level of granularity you pick determines how convenient Tropy’s UI will be to navigate your data: since you can group items via tags and lists (which can also be nested) I would say that ideally an item should have somewhere between 1-20 photos if each photo contains substantial metadata; if most of the photos are not annotated individually, and you have a large data-set (like 10,000 photos or more) it might be better to have more photos per item, but keep in mind that Tropy’s UI is designed to make it easy to find items; currently there’s no shortcut to finding individual photos within a given item.
In any case, a good way to start, I think, is to just create a project for testing with one or two sample items based on your current data. You can then export these items to JSON-LD (or just copy the items and paste them into a text editor) to see what the JSON data looks like.
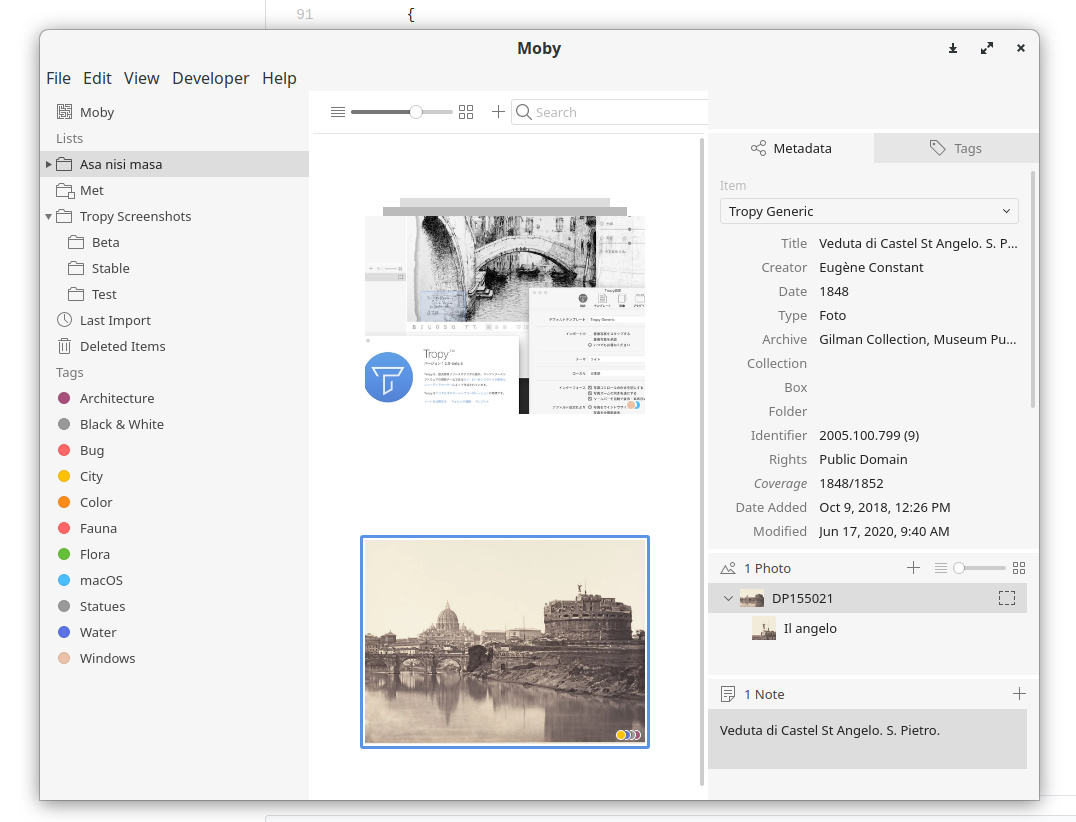
For illustration purposes, I created a Gist with some examples: here you see the JSON exported by Tropy for two items you can see in the screenshot below, with multiple photos, selections and notes each.
Don’t be worried by the complexity! Tropy will make some informed assumptions on import, so you will be able to compile a much simpler structure. For example, here are the same items, but simplified considerably. You can go ahead and try to copy paste both of these JSON data into a Tropy project and you should be able to view the results (I have not attached the photos themselves, so you will not be able to import everything). A few notes on the simplified JSON:
- You can omit the JSON-LD
@context completely. This means that you have to use full property ids for your own metadata values: note how the simplified JSON uses the full dc:title id instead of just title as in the original export.
- You can also omit the wrapping object and
@graph and instead just import an array of items.
- By default, Tropy will export absolute paths to your photos. This is fine for copy/pasting on the same device. If you import remote photos (protocol ‘http’ or ‘https’ instead of ‘file’) you can typically just paste the JSON on a different device and Tropy will be able to download all photos. In most other cases, the paths to your photos can also be relative: in this case Tropy will resolve the path relative to your JSON file during import. In the simplified example, I made all the paths relative to illustrate this (this is also what Tropy’s archive plugin does by the way). In your case, the best approach would be to arrange your files in your preferred way on your drive and put relative paths into the JSON file you generate: Tropy will then find all your photos on import.
- You can also omit most of the data that Tropy can extract from your files (e.g., file size, width, height, etc.). There is currently a limitation that Tropy expects the
mimetype and checksum values to be present. This will not be necessary anymore in future versions, but for the time being you need to insert those values even if you just put in arbitrary data: Tropy will compute the actual checksum and set the mime-type accordingly when it imports the files.
- You can also omit most of the advanced filter properties (brightness, angle, sharpen, etc.). Tropy will just fallback to default values for those.
Right, I hope this is helpful. Don’t hesitate to get in touch if you run into any issues when converting your data or if you have any questions!